
N-gram Smoothing Techniques
Approximate the probability of an unobserved N-gram using more frequently occuring lower order N-grams If an N-gram count is zero we approximate its probability using a lower order N-gram. For example in recent years Pscientist data has probably overtaken Panalyst data.
2
Which smoothing algorithm is easy and effective in case of implementation point of view.

N-gram smoothing techniques. Extremely popular for N-gram modeling in speech recognition because you can control complexity as well as. This is type Increment normalization factor by Vocabulary size. Although smoothing techniques can be traced back to Lidstone 1920 or even earlier to Laplace 18th century an early application of smoothing to n-gram models for NLP is by Jelinek and Mercer 1980.
More smoothing techniques are proposed in the 1990s. With more parameters data sparsity becomes an issue again but with proper smoothing the models are usually more accurate than the original models. If any N-gram is missing then the language model will give a probability of zero to it and infinite value can be resulted.
Thus no matter how much data one has smoothing can almost always help performace and. It proceeds by allocating a portion of the probability space occupied by n-grams which occur with count r1 and dividing it among the n-grams which occur with rate r. N-Gram Smoothing Techniques - YouTube.
For example we will have unigram bigram and trigram language models and we will weight them with some lambda coefficients and this lambda coefficients will sum into one so we will still get a normal probability. The smoothing method proposed by Lin and Och 30 is used in B-Norm to smooth the calculation of n-gram precision scores. So the Interpolation smoothing says that let us just have the mixture of all these n-gram models for different end.
That is needed because in some cases words can appear in the same context but they didnt in your train set. Good-Turing smoothing is a more sophisticated technique which takes into account the identity of the particular n-gram when deciding the amount of smoothing to apply. In a bit of terminological ambiguity we usually drop the word model and use the term n-gram and bigram etc to mean either the word sequence itself or the predictive model that assigns it a probability.
Holt Winters Smoothing introduces a third parameter g to account for seasonality or periodicity in a data set. Each smoothing technique suffers from different limitations and selecting the appropriate. Smoothing Summed Up Add-one smoothing easy but inaccurate Add 1 to every word count Note.
All the counts that used to be zero will now have a count of 1 the counts of 1 will be 2 and so on. The file name containing data for which you need to make predictions. A zero frequency N-gram can be modeled by the probability of seeing an N-gram for the first time.
The interpolated Kneser-Ney smoothing algorithm mixes a discounted probability with a lower-order continuation probability. Bigram trigram is a probability estimate of a word given past words. Well see how to use n-gram models to estimate the probability of the last word of an n-gram given the previous words and also to assign probabilities to entire se-quences.
Good Turing builds on this intuition to allow us to estimate the probability mass assigned to n-grams with lower counts by looking at the number of n-grams with higher counts. An n-gram model is a type of probabilistic language model for predicting the next item in such a sequence in the form of a n 1order Markov model. It adds a constant number one to both the numerator and denominator of p.
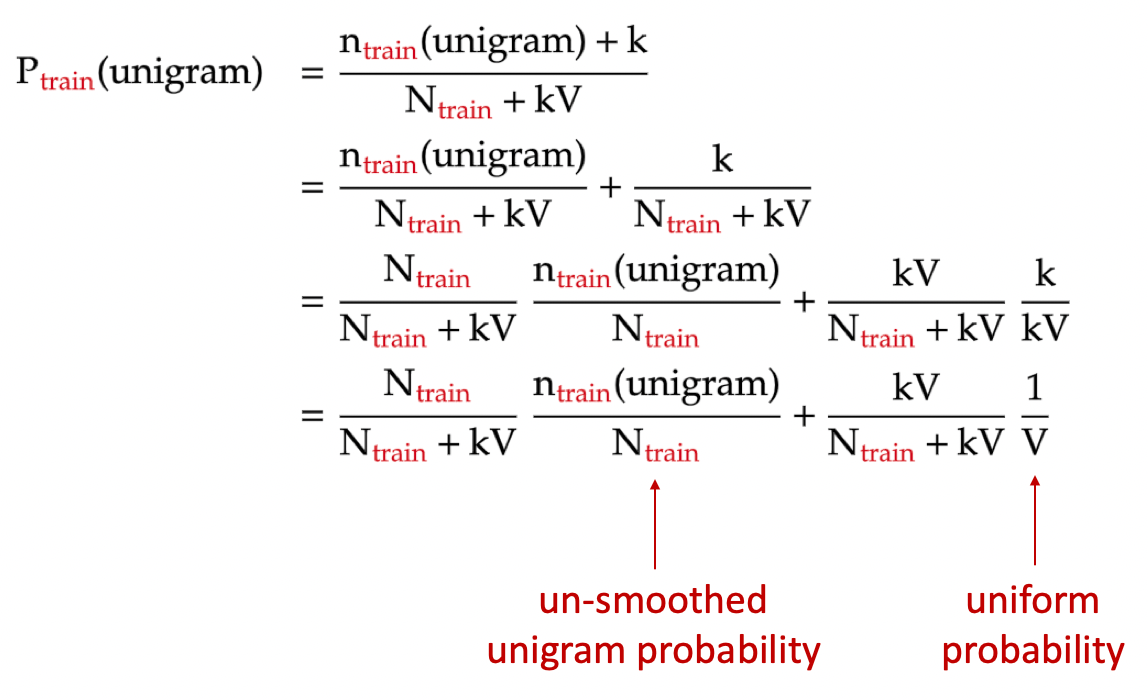
Add-One Smoothing For all possible n-grams add the count of one c count of n-gram in corpus N count of history v vocabulary size But there are many more unseen n-grams than seen n-grams Example. N-gram probability smoothing for natural language processing An n-gram ex. 86700 distinct words 86700 2.
The purpose of smoothing is to prevent a language model from assigning zero probability to unseen events. If the trend parameter is 0 then this technique is equivalent to the Exponential Smoothing technique. The N for N-gram model.
And eventually I need smoothing. Kneser-Ney smoothing makes use of the probability of a word being a novel continuation. Katz smoothing Katz smoothing.
Commonly used smoothing algorithms for n-grams rely on lower-order n-gram counts through backoff or interpolation. However results may not be identical due to different initialization methods for these two techniques Holt-Winters Smoothing. Smoothing is a task used to prevent assigning zero probability for missing N-gram in corpus 5.
The train set file name. Command Line Arguments Compulsory arguments. Expand the model such as by moving to a higher n-gram model to achieve improved performance.
Smoothing techniques in NLP are used to address scenarios related to determining probability likelihood estimate of a sequence of words say a sentence occuring together when one or more words individually unigram or N-grams such as bigramw_iw_i-1 or trigram w_iw_i-1w_i-2 in the given set have never occured in the past. The K for add-K Smoothing No smoothing when K 0. They are called unknown words.
Material based on Jurafsky and Martin 2019. While n-gram models are much. A better smoothing technique is due to Katz 1987.
N tokens V types Backoff models When a count for an n-gram is 0 back off to the count for the n-1-gram These can be weighted trigrams count more 39. 2 n -gram models are now widely used in probability communication theory computational linguistics for instance statistical natural language processing computational biology for instance biological sequence analysis and data compression. This algorithm is called Laplace smoothing.
Smoothing is a quite rough trick to. The scaling factor is chosen to make the conditional distribution sum to one. Laplace smoothing does not perform well enough to be used in modern n-gram models but it usefully introduces many of the concepts that we see in other smoothing algorithms.
Put the java program and the datasets under the same directory. My training corpus is a hex dump looks like 64 FA EB 63 31 D2 62 22 19 BD 64 B5 63 17 4F 48 62 A8 64 11 0F 62 15 9B 64 9B 1F E1 63 62 BE 63 I would like to build a 2345-gram language model on it.

N Gram Language Model Laplace Smoothing Zero Probability Perplexity Bigram Trigram Fourgram Youtube

N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium
2
2

Ppt Smoothing N Gram Language Models Powerpoint Presentation Free Download Id 2384790

Introduction To N Grams Ppt Video Online Download

N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium
N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium

N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium

Ppt Smoothing N Gram Language Models Powerpoint Presentation Free Download Id 2384790
N Grams Models Laplace Smoothing Youtube

N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium

N Gram Language Models Part 1 The Unigram Model By Khanh Nguyen Mti Technology Medium

Smoothing N Gram Language Models Shallow Processing Techniques For Nlp Ling570 October 24 Ppt Download
Posting Komentar untuk "N-gram Smoothing Techniques"